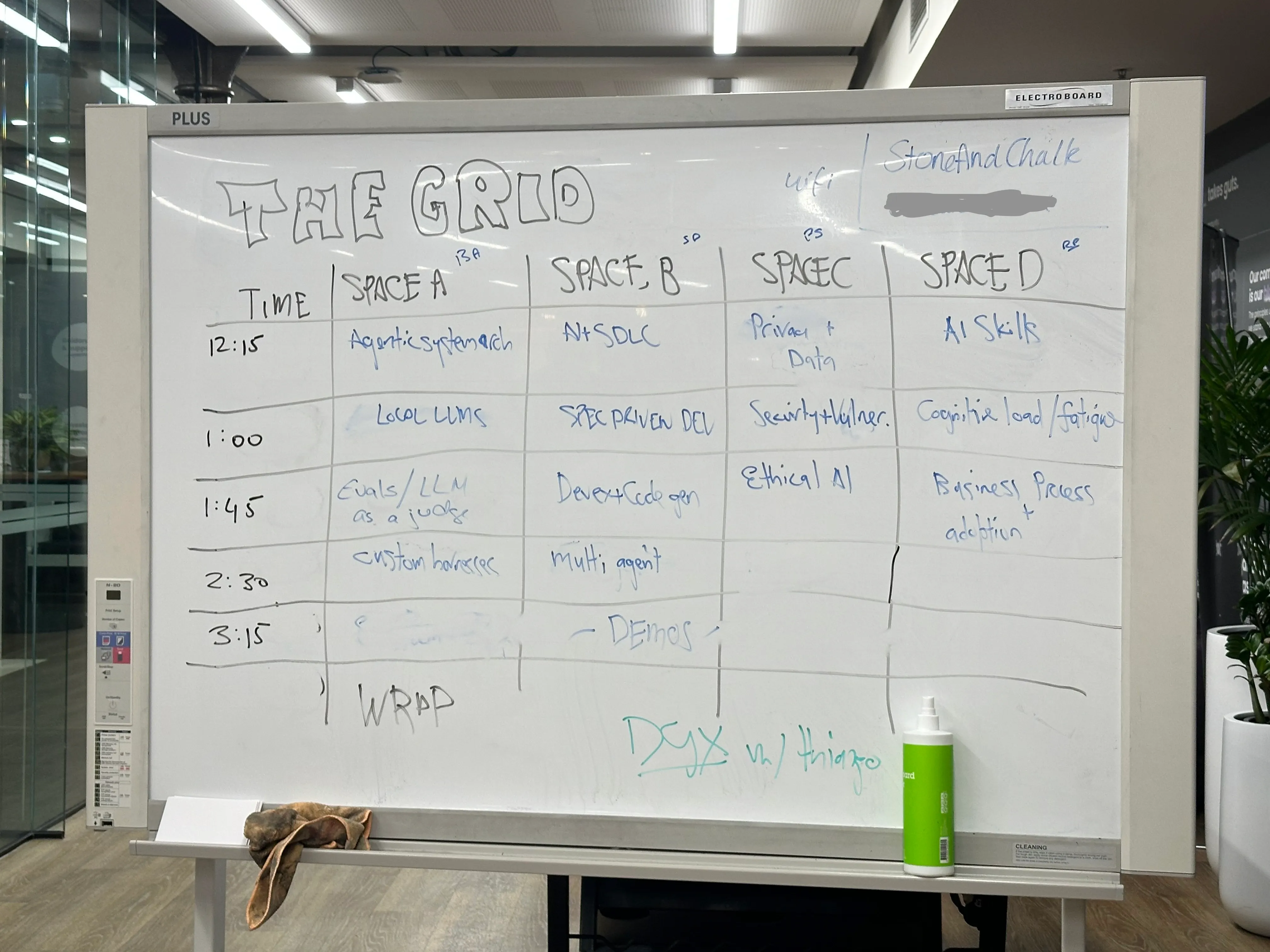
Lessons from Melbourne's AI Engineering Unconference: evals consume 50% of engineering time, synthetic scenarios unlock tacit knowledge from domain experts, and the real bottleneck in AI engineering is organisational — not technical.
Contents
The bottleneck has moved
Every session circled back to the same thing: code generation is not the hard part anymore. AI can produce code fast. The hard part is now upstream (requirements, domain knowledge, planning) and downstream (testing, evaluation, deployment).
I hosted the AI SDLC session and presented a framework I've been working on that maps the traditional software lifecycle against AI capabilities: rules (like Claude MD files), tools (MCP integrations), skills, automations, and orchestrators. We recently ran a workshop where engineers tried to use AI end to end from planning to deployment. Half day. We only got through plan, design, test, and build. Deployment and monitoring have massive untapped potential but we just ran out of time.
The irony isn't lost on anyone. AI has made code generation trivially fast, but organisations can't move their surrounding processes any faster. One enterprise consultant put it bluntly: "I need to deploy but it's in an Azure environment managed by a third party. I need someone to spin up a server. Four weeks." You can write code in an hour but if your security review takes a month, you haven't actually accelerated anything.
Evals: the 50% tax you can't avoid
The evals session was easily the best conversation of the day. Practitioners in the room were building compliance platforms, student tutoring apps, insurance claim assessors, all of them wrestling with the same question: how do you know it's working?
At Freshwater Futures we built an eval system into our Agent Platform that's designed for non technical users. They click into a conversation, see colour coded outputs, and mark them pass, fail, needs review, or irrelevant. There's a workflow for marking things as fixed and tested, almost like a bug tracker baked into the eval process. We planned to build LLM-as-judge automation on top of it but never actually needed it. At the scale we were operating, we could fix issues through prompt engineering as they appeared, and the same bug rarely came back twice.
The thing that got the most interest from the room was our scenario generator. Before we had any real user data, we needed test cases. So we built a tool that generates synthetic scenarios from the agent's domain, then plays both sides of the conversation. A hundred fake conversations in a day, handed to assessors. You learn an enormous amount in one iteration. It basically bootstraps the whole evals process from nothing.
The group landed on three roles for LLM-as-judge in production. Observability: sampling and annotating live system performance. Production gatekeeping: checking whether a new model or prompt is safe to ship. And real time guardrails: catching bad outputs at inference time before they reach users.
For a student tutoring platform one participant went with real time guardrails because child safety had to be 100%. Every response was checked. Did the AI ask for personal information? Did it give away the answer instead of tutoring? Was the language above the student's reading grade? If any check failed, the response went back for regeneration before the student saw it.
Some things I took away from the room:
Evals ate about 50% of engineering time on the projects discussed. Budget for that. One team forgot to book time with subject matter experts for human evaluation and had to scramble at the end of the project to find calendar slots. Politically painful.
You need about 10x more test scenarios than you think you do. Everyone learns this the hard way.
Not everything needs an LLM. Regex catches credit card numbers. Small models catch entity names. Use the cheapest tool that works.
And if you're using production data to improve your system, that has compliance implications. A CTO building an ISO compliance platform reminded the room that user opt ins matter, especially in regulated industries.
Spec driven development: old school is new school
This session had an interesting premise: in an AI world, code is an output, not the source of truth. Specs are. Which sounds a lot like waterfall, except nobody wants to say that.
In the old world, specs were written for human coders who could fill in gaps with intuition. Now specs are being written for agents, and they need to be much more specific. Someone proposed a test: if two different agents independently build from the same spec, the functional result should be identical. That's a high bar.
On participant kept pushing on how this works with agile. You rarely know all the requirements upfront, so how much spec do you actually write? The group converged on something I found compelling: use AI to rapidly prototype, show it to users, then derive the spec from their feedback. I shared a skill that interviews users while simultaneously generating HTML mockups, pulling exploratory and validation research into a single conversation — part of our rapid prototyping approach.
A product owner nailed the underlying dynamic: "No one knows what they want until they get it, but they're very quick to tell you what they don't want." So build fast, show it, capture the feedback, write the spec. That's going to be more accurate than any requirements document signed off in a meeting room.
The group's main caution: be careful with proof of concepts. If a POC looks good enough, stakeholders start asking why it can't just go to production. A POC has different non functional requirements than a production system, and that gap creates dangerous expectations about timelines and cost.
Getting expertise out of people's heads
The hardest problem that came up in the AI SDLC and Spec Driven Development sessions was extracting tacit knowledge from domain experts. An enterprise consultant shared a case where they're building AI to consolidate engineering comments on infrastructure drawings, taking hundreds of comments down to a few. The domain experts, civil and structural engineers, couldn't articulate their decision logic as rules. Their answer was often: "When I see it, I'll know what to do with it."
I've hit this too. For a financial services client we built an insurance chatbot and the claims assessors couldn't tell us how they made decisions. So we generated hundreds of synthetic scenarios, ran them through the AI agent, and showed the traces to the assessors. They immediately told us everything that was wrong. One particular expert was unstoppable. "Don't get me started. You forgot this, this, this, and this." We recorded those sessions, fed the corrections back into our prompts and knowledge bases, and iterated. We almost didn't need the eval framework, because the synthetic scenarios themselves were the thing that unlocked what these people knew.
Sometimes the value of evals isn't catching bugs. It's making invisible expertise visible.
Is scrum dead?
Someone asked whether this is the end of scrum. Claude Code updates every 15 minutes. That breaks sprint cycles. The room pushed back: sprint planning still matters because it sets direction. Without it you're just building features for the sake of it. But the mechanics have to change. Planning and testing are the high value work now. Code generation sits in between and takes almost no time.
The bigger question is whether organisations can redesign procurement, security review, and deployment approvals to match the speed that AI engineering enables. Startups with no rules can do this trivially. Government organisations with 10x contract liability and four week server provisioning? That's where the real friction is.
What I'm taking away
Start your evals during requirements gathering, not after you've built the thing. Day zero, not day one.
Synthetic scenarios are maybe the best trick we've found for unlocking tacit knowledge. Build something, even something wrong, show it to experts. They'll tell you things they couldn't have told you in a meeting.
We've barely scratched the surface of AI in the software lifecycle. Plan, design, and build are getting attention. Deployment and monitoring are wide open.
Spec driven development has legs, but specs have to be living documents that come from rapid prototyping, not upfront waterfall artefacts.
And the bottleneck is organisational, not technical. Code generation is a solved problem. Requirements, approvals, deployment, feedback loops: that's where the work is now.
If you're in Melbourne and working with AI in any engineering capacity, I'd recommend showing up to one of these type of events or attending the AI Engineer conference. The conversations are worth it.
Frequently Asked Questions
- An unconference is a participant-driven event where attendees propose and vote on session topics on the day. The AI Engineering Unconference in Melbourne brought together engineers, product managers, consultants and data scientists to discuss practical challenges in building with AI.
- Based on projects discussed at the unconference, evals consumed roughly 50% of total engineering time. Teams should budget for this upfront and book subject matter experts for human evaluation early in the project timeline.
- Synthetic scenarios are AI-generated test conversations that simulate real user interactions across a domain. They bootstrap the evaluation process before you have real user data, and are particularly effective at extracting tacit knowledge from domain experts who struggle to articulate their decision-making rules.
- The group identified three roles: observability (sampling and annotating live performance), production gatekeeping (validating whether a new model or prompt is safe to ship), and real-time guardrails (checking outputs at inference time before they reach users).
- Not exactly. While specs become the source of truth (similar to waterfall), the approach is to use AI to rapidly prototype first, show it to users, then derive the spec from their feedback. The spec is a living document that evolves through iteration, not an upfront artefact signed off in a meeting room.
- The bottleneck has shifted from code generation to organisational processes. Enterprise procurement, security reviews, deployment approvals, and server provisioning can take weeks or months, while AI can generate code in minutes. The surrounding processes haven't caught up.
- Generate synthetic scenarios, run them through the AI system, and show the outputs to domain experts. They can't always articulate their decision logic as rules, but they can immediately identify what's wrong when they see AI-generated outputs. Record these sessions and feed corrections back into prompts and knowledge bases.
- Not dead, but changing. Sprint planning still matters for setting direction, but the mechanics need to adapt. Planning and testing are now the high-value work. Code generation sits in between and takes almost no time. The bigger challenge is redesigning procurement, security review, and deployment approvals to match AI-enabled speed.
Get Started
We'll help you build it.
About Freshwater Futures
If you're looking to adopt AI across your software development lifecycle, Freshwater Futures runs hands-on workshops and transformation programs that help engineering teams go from planning to deployment with AI. We also build custom AI agents with built-in evaluation frameworks. Get in touch to discuss how we can help your team.
Ben is the founder of Freshwater Futures, where we help organisations adopt AI across their software development lifecycle.